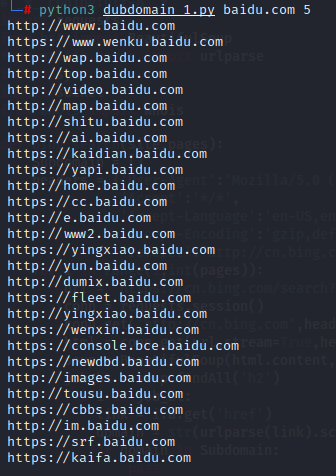
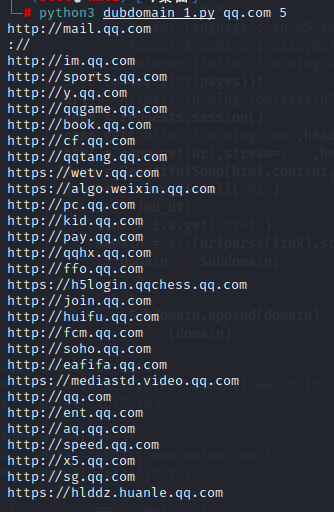
Python练习:子域名
这个tag是为了记录一下学习python的过程,收录的都是练手的一些代码,这篇是一个很简单的借助搜索引擎收集子域名的小脚本,构造好http包,然后借助搜索语法,利用搜索引擎进行查询,之后收集查询到的域名,再把收集到的域名去重,打印出来。
下面这个是这个小脚本的核心部分,bing_search函数,这里是使用了bing搜索引擎做了一个子域名的收集,师傅们可以做些修改,能上谷歌的可以改成google hacker语法,功能会更好些
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def bing_search(site,pages):
Subdomain = []
#填充http头
headers = {'User-Agent':'Mozilla/5.0 (xll;Linux x86_64;rv:60.0) Gecko/20100101 Firefox/60.0',
'Accept':'*/*',
'Accept-Language':'en-US,en;q=0.5',
'Accept-Encoding':'gzip,deflate',
'referer':"http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsite%3abaidu.com&first=2&FORM=PERE1"}
#循环发送请求查询,并记录域名等信息
for i in range(1,int(pages)):
url = "https://cn.bing.com/search?q=site%3a"+site+"&go=Search&qs=ds&first="+ str((int(i)-1)*10) +"&FORM+PERE"
conn = requests.session()
conn.get('http://cn.bing.com',headers=headers)
html = conn.get(url,stream=True,headers=headers,timeout=8)
soup = BeautifulSoup(html.content,'html.parser')
job_bt = soup.findAll('h2')
#嵌套循环,这里用到了urlparse,urlparse会将url解析为六个部分,这里的scheme是协议,netloc是域名服务器
for i in job_bt:
link = i.a.get('href')
domain = str(urlparse(link).scheme+"://"+urlparse(link).netloc)
#判重
if domain in Subdomain:
pass
else:
Subdomain.append(domain)
print(domain)
|
下面是整个小工具的源码部分,一开始考虑到往里面加上域名-ip的反查和whois查询,后来想了一下,不是特别有必要,于是就去掉了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import sys
import socket
from whois import whois
def bing_search(site,pages):
Subdomain = []
headers = {'User-Agent':'Mozilla/5.0 (xll;Linux x86_64;rv:60.0) Gecko/20100101 Firefox/60.0',
'Accept':'*/*',
'Accept-Language':'en-US,en;q=0.5',
'Accept-Encoding':'gzip,deflate',
'referer':"http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsite%3abaidu.com&first=2&FORM=PERE1"}
for i in range(1,int(pages)):
url = "https://cn.bing.com/search?q=site%3a"+site+"&go=Search&qs=ds&first="+ str((int(i)-1)*10) +"&FORM+PERE"
conn = requests.session()
conn.get('http://cn.bing.com',headers=headers)
html = conn.get(url,stream=True,headers=headers,timeout=8)
soup = BeautifulSoup(html.content,'html.parser')
job_bt = soup.findAll('h2')
for i in job_bt:
link = i.a.get('href')
domain = str(urlparse(link).scheme+"://"+urlparse(link).netloc)
if domain in Subdomain:
pass
else:
Subdomain.append(domain)
print(domain)
if __name__ == '__main__':
if len(sys.argv)==3:
site = sys.argv[1]
page = sys.argv[2]
else:
print("usage: %s baidu.com 10" % sys.argv[0])
sys.exit(-1)
Subdomain = bing_search(site,page)
|
使用测试:
收集的并不是很全,毕竟方法比较原始,代码也比较简单,以后再接再厉